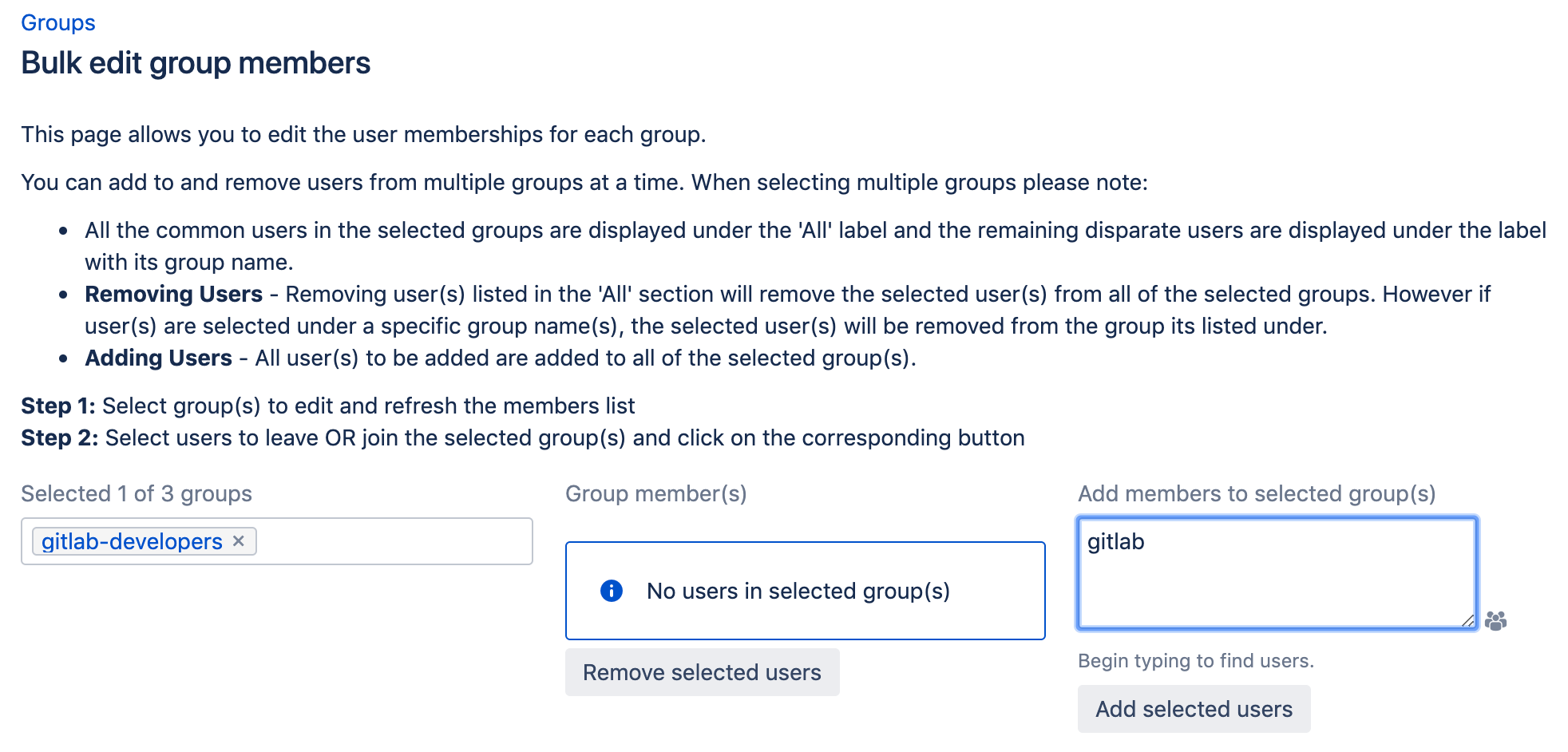
تا به حال شده رییستان از شما بخواهد میزان فروش این ماه (و البته ماه های قبل) شرکت را برایش آماده کرده و شرح دهید؟!
در این صورت شما دو راه دارید، یا یک جدولِ بزرگِ پر از اعداد، شامل درآمد در ماه های مختلف را تقدیم حضور رییستان کنید، که نه به درد ایشان میخورد و نه به درد شما، و یا اینکه، پس از بررسی دقیق آن جدول، مفهومی که قرار است از طریق آن جدول منتقل شود را در قالب چند شکل و نمودارِ ساده اما جذاب، به ایشان ارایه دهید.

حتما شنیده اید که:
گاهی یک تصویر، گویا تر از هزاران واژه است.
واقعا هم همینطور است، ساختار ذهنی انسان طوری شکل گرفته که یک تصویر ساده را بسیار سریع تر و راحت تر از هر چیز دیگری درک میکند.
یک مدیر ارشد اجرایی (CEO) وظایف سنگینی دارد که زمانی را برای سر و کله زدن با داده ها و جدول های عددی و یافتن مفهوم درون آن ها باقی نمیگذارند. بنابراین، این شخص برای انجام وظایف خود و گرفتن تصمیم های سازمانی درست، نیاز به درک سریع و دقیقِ مفهومِ نهفته در این جدول های عددی دارد. از همین رو امروزه مدیران شرکت های بزرگ، از دانشمندان دادهها (Data Scientist ها) و مهندسان هوشمندی در کسب و کار (BI Engineer ها) برای تحلیل داده ها، به تصویر کشیدنِ آنها و تصمیم گیری بر اساس داده ها (Data-driven strategy) بهره میبرند.

به تصویر کشیدن داده ها (Data Visualization) یکی از اصلی ترین و مهم ترین موضوعات در Data Science است که با نمودار های آماری، گراف ها، پلات ها و اشکال سر و کار دارد. با این وجود، هدف از این پُست، مطالعه ی کاملِ متد های Data Visualization نیست بلکه آشنایی با مهمترین نمودارهای آماریِ مورد استفاده در Data Science است. ازین رو مطالعه این پست را به تمامی دانشجویان، پژوهشگران، مهندسان، اهالی کسب و کار و مدیران (فارغ از رشته تحصیلی و کاری) پیشنهاد میدهیم.
در اینجا فرض میشود که شما یک مجموعه دادهها (Dataset) شامل چندین سطر (Observation یا Experience یا Data Point) و چندین ستون (Feature یا Variable یا Attribute) دارید و میخواهید با رسم نمودار های آماری مرتبط (که در زیر معرفی خواهند شد)، به یک بینش در رابطه با مجموعه دادهها دست پیدا کنید.
۱. نمودار Histogram
از این نمودار برای بررسی و مطالعه ی توزیعِ آماریِ یک متغیر عددی (Numerical Variable) استفاده میشود. معمولا اولین کاری که در مواجهه با یک Dataset میکنیم، بررسی توزیع آماریِ تکتکِ متغیر ها (Feature ها) ی آن است. درکِ توزیعِ آماریِ متغیر ها به ما کمک میکند تا اشتباهات موجود در داده ها (مانند نویز ها و خطا های اندازه گیری) را کشف کنیم. برای رسم نمودار Histogram، بازه (Range) مقادیرِ مشاهده شده برای متغیر را به تعدادی فاصله ی هم اندازه (bin) تقسیم کرده و فراوانی (تعداد) مشاهدات در هر فاصله را به صورتِ ارتفاعِ یک میله نمایش میدهیم.

ممکن است هیستوگرامِ مربوط به چند متغیر، برای مقایسه، در یک نمودار و با رنگ های مختلف نشان داده شوند، اما معمولا برای مطالعه ی همزمانِ توزیعِ آماریِ چند متغیر، از نمودار های دیگر (مثل نمودار Boxplot، نمودار Violin Plot و یا نمودار Ridgeline Plot) استفاده میشود.
برای کسب اطلاعات بیشتر در رابطه با Histogram اینجا کلیک کنید.
برای آشنایی با روشِ رسم Histogram در زبان برنامهنویسی Python اینجا کلیک کنید.
۲. نمودار Density Plot
این نمودار در واقع شکل صیقل داده شده ی نمودار Histogram است و تابعی به نام Probability Density Function را برای یک متغیرِ عددی به تصویر میکشد.

برای کسب اطلاعات بیشتر در رابطه با Density Plot اینجا کلیک کنید.
برای آشنایی با روشِ رسم Density Plot در زبان برنامهنویسی Python اینجا کلیک کنید.
۳. نمودار های 2D Histogram و 2D Density Plot
این دو نمودار برای مطالعه ی توزیعِ آماریِ دو متغیرِ کمّی (عددی) در ترکیب با هم، استفاده میشوند. برای رسم نمودار 2D Histogram، یکی از متغیر ها را روی محور X و دیگری را روی محور Y در نظر گرفته و با استفاده از bin ها صفحه مختصات دوبعدی را به یک جدول (Grid) تبدیل میکنیم. سپس تعداد مشاهدات در هر قسمت از Grid را توسط طیف رنگ ها نمایش میدهیم (مثلا برای مقادیر کم از بنفش و برای مقادیر زیاد از قرمز استفاده میکنیم)

نمودار 2D Density Plot هم صیقل داده شده ی 2D Histogram است.

این دو نمودار، زمانی که تعداد مشاهدات زیاد است کارایی دارند و برای تعداد مشاهدات کم، نمودار های دیگر (مثل Scatter Plot) اطلاعات دقیق تری را منتقل میکنند.
برای کسب اطلاعات بیشتر در رابطه با 2D Histogram و 2D Density Plot اینجا کلیک کنید.
برای آشنایی با روشِ رسمِ 2D Histogram و 2D Density Plot در زبان برنامهنویسی Python اینجا کلیک کنید.
۴. نمودار Ridgeline Plot یا Joyplot
این نمودار شامل چند Histogram یا 2D Density Plot با مقیاس یکسان است که معمولا برای مقایسه ی توزیعِ آماریِ یک متغیرِ عددی برای چندین گروهِ مختلف استفاده میشود. Ridgeline Plot معمولاً وقتی کارایی خود را نشان میدهد که الگوی مشخصی بین مقادیرِ گروه ها وجود داشته باشد. به عنوان مثال در شکل میبینید که این مقادیر از پایین به بالا زیاد شده اند و نمودار ها روی هم نیفتاده اند.


در این نوع نمودار، ترتیب درست گروه ها، تاثیر بسزایی در خوانایی نمودار دارد.
برای کسب اطلاعات بیشتر در رابطه با Ridgeline Plot اینجا کلیک کنید.
برای آشنایی با روشِ رسم Ridgeline Plot در زبان برنامهنویسی Python اینجا کلیک کنید.
۵. نمودار Box Plot
این نمودار، خلاصه ای از اطلاعاتِ آماریِ مربوط یک متغیر کمّی، برای چندین گروه مختلف را به تصویر میکشد. به عبارت دیگر، خطی که box ها را به دو نیم تقسیم میکند، نشان دهنده ی میانه (Median) داده های مشاهده شده برای متغیر، و ابتدا و انتهای box ها نشان دهنده ی چارک اول (Lower Quartile) و چارک سوم (Upper Quartile) آنها اند. خطوط انتهایی نیز نمایانگر کوچکترین و بزرگترین داده ی مشاهده شده (صرف نظر از داده های پَرت یا Outlier ها) اند. Outlier ها (به عنوان نمونه، نویز ها یا داده های ناشی از خطای اندازه گیری) نیز با نقطه در نمودار زیر نشان داده شده اند.

گاهی میخواهیم توزیع آماری داده های مشاهده شده را نیز در Box Plot نمایش دهیم. اگر تعداد مشاهدات کم است، میتوانیم آن مشاهدات را با نقطه روی نمودار نشان دهیم تا نحوه توزیع آنها مشخص شود. اما اگر تعداد مشاهدات زیاد است، این روش کارایی ندارد و به جای آن از نمودار های دیگر (مثل Violin Plot) استفاده میشود.

برای کسب اطلاعات بیشتر در رابطه با Box Plot اینجا کلیک کنید.
برای آشنایی با روشِ رسمِ Box Plot در زبان برنامهنویسی Python اینجا کلیک کنید.
۶. نمودار Violin Plot
این نمودار زمانی استفاده میشود که میخواهیم توزیع آماری تعداد زیادی داده را در Box Plot داشته باشیم، اما نمایش همه داده ها روی نمودار از خوانایی آن میکاهد. Violin Plot با ترکیب نمودار های Box Plot و Ridgeline Plot این کار را به راحتی انجام میدهد.

برای کسب اطلاعات بیشتر در رابطه با Violin Plot اینجا کلیک کنید.
برای آشنایی با روشِ رسمِ Violin Plot در زبان برنامهنویسی Python اینجا کلیک کنید.
۷. نمودار Scatter Plot
از این نمودار برای نمایشِ رابطه و همبستگیِ میانِ دو متغیرِ کمّی استفاده میشود. متغیر ها را توسط محور های مختصات دکارتی به تصویر کشیده و به ازای هر داده ی مشاهده شده در Datset یک نقطه از فضای مختصات را با دایره پُر میکنیم. اگر بین متغیر ها، رابطه و همبستگی وجود داشته باشد، در نمودار Scatter Plot، قابل تشخیص است. به عنوان مثال، نمودار بالا سمت راست در تصویر زیر، نشان دهنده ی یک رابطه خطی بین دو متغیر است چون به نظر میرسد نقاط، روی یک خط پراکنده شده اند. رابطه خطی به این معنی است که اگر مقدار یکی از متغیر ها n برابر شود، مقدار متغیر دیگر نیز n برابر میشود. یا نمودار پایین سمت راست، معرف یک رابطه سینوسی بین دو متغیر است.

بسیاری از اوقات در حل مسایل Data Science، بررسی همه متغیر ها (Feature ها) امکان پذیر نیست و مایلیم متغیر های مهم تر را انتخاب و بررسی کنیم. یافتن همبستگی بین متغیر ها به ما کمک میکند متغیر هایی که قابل پیش بینی از روی سایر متغیر ها هستند را برای سادگی بیشتر حذف کنیم. به این کار اصطلاحا Feature Selection گفته می شود.
همبستگی بین دو متغیر در Scatter Plot را میتوان توسط یک منحنی فیت شده روی مشاهدات به نام Trend Curve نشان داد.

وقتی تعداد مشاهدات زیاد نیست، نحوه ی توزیعِ آماری داده ها در Scatter Plot مشخص است. اما زمانی که تعداد مشاهدات زیاد باشد، پدیده ی Overplotting روی نمودار رخ داده و خوانایی آن را از بین میبرد. در این صورت برای مشخص شدن توزیع آماری، یا از نقطه های Transparent در Scatter Plot استفاده میکنیم یا از نمودار 2D Density Plot.


ضمناً گاهی برای مشخص نمودن توزیع آماریِ مشاهدات، از Histogram یا Density Plot در حاشیه ی Scatter Plot استفاده میشود.

گاهی برای دسته بندی مشاهدات در Scatter Plot (افزودن یک متغیر غیر عددی یا Categorical به نام دسته) از رنگ های مختلف برای نمایش نقاط استفاده میشود. در این صورت حتما باید از یک راهنما (Legend) در نمودار استفاده کرد.

اگر بخواهیم یک متغیر عددی (غیر Categorical) را به عنوان متغیر سوم به Scatter Plot اضافه کنیم، به جای رنگ میتوان سایز نقطه ها را تغییر داد (نمودار Bubble Plot).
برای کسب اطلاعات بیشتر در رابطه با Scatter Plot اینجا کلیک کنید.
برای آشنایی با روشِ رسمِ Scatter Plot در زبان برنامهنویسی Python اینجا کلیک کنید.
۸. نمودار Bubble Plot
این نمودار، در واقع همان Scatter Plot است که یک متغیر عددی سوم توسط اندازه دایره ها (حباب ها) در آن نشان داده شده است.

برای کسب اطلاعات بیشتر در رابطه با Bubble Plot اینجا کلیک کنید.
برای آشنایی با روشِ رسمِ Bubble Plot در زبان برنامهنویسی Python اینجا کلیک کنید.
۹. نمودار Correlogram
وقتی با یک Dataset شامل چند متغیر عددی روبهرو میشویم، مطالعه ی توزیع آماری تک تک متغیر ها با استفاده از Density Plot و همینطور مطالعه ی همبستگی بین هر دو متغیر عددی با استفاده از Scatter Plot اولین کاری است که انجام میدهیم. نمودار Correlogram یا Correlation Matrix خلاصه ی نتایج این فعالیت ها را در قالب یک نمودار نمایش میدهد.
این نمودار، به شکل یک ماتریس است که متغیر ها در سطر و ستون آن تکرار شده اند. قطر اصلی این ماتریس شامل Histogram و یا Density Plot هایی برای بررسی توزیع آماری متغیر ها و سایر درایه های آن شامل Scatter Plot هایی برای بررسی رابطه بین متغیر ها هستند.


برای کسب اطلاعات بیشتر در رابطه با Correlogram اینجا کلیک کنید.
برای آشنایی با روشِ رسمِ Correlogram در زبان برنامهنویسی Python اینجا کلیک کنید.
۱۰. نمودار Connected Scatterplot
برای نمایش رَوَندِ تکاملِ یک متغیرِ کمّی و یا برای نمایش Trend در دیتا طی بازه های زمانی مختلف (سریِ زمانی یا Time Series) مانند نوسانات قیمت Bitcoin در یک بازه زمانی و یا دنباله ی سیگنال های الکتریکی اندازه گیری شده در یک دستگاه، میتوان از نمودار Connected Scatterplot استفاده کرد. در این نمودار، دنباله مشاهدات به صورت نقاطی که با خط صاف به هم متصل شده اند نمایش داده می شود.

اگر تعداد مشاهدات زیاد باشد (مثلا مطالعه قیمت Bitcoin طی ۵ سال متوالی)، دایره ها باعث ناخوانا شدن نمودار میشوند. بنابراین در چنین شرایطی، با حذف دایره ها نموداری به نام Line Chart رسم میکنیم.
برای کسب اطلاعات بیشتر در رابطه با Connected Scatterplot اینجا کلیک کنید.
برای آشنایی با روشِ رسمِ Connected Scatterplot در زبان برنامهنویسی Python اینجا کلیک کنید.
۱۱. نمودار Line Chart
با حذف دایره ها از Connected Scatterplot نموداری متشکل از فقط خطوط متصل کننده نقاط به نام Line Chart پدید میآید که برای نمایش نوسانات طولانی مدت (مشاهدات زیاد)، خوانا تر است.
اگر تعداد مشاهدات، محدود است، Connected Scatterplot اطلاعات بیشتری را منتقل میکند.

از Line Chart میتوان برای نمایش نوسانات و تکامل چندین متغیر عددی به طور همزمان استفاده کرد. با این حال باید توجه شود که اگر تعداد متغیر های مورد بررسی زیاد باشد، این نمودار خوانایی خود را از دست داده و به چیزی به نام Spaghetti Chart تبدیل میشود.

معمولا هدف از نمایش همزمان چند متغیر در یک Line Chart مقایسه یکی از آنها با بقیه است. در چنین حالتی میتوانید با برجسته کردن نمودار آن متغیر و کمرنگ کردن بقیه از تبدیل شدن نمودار به Spaghetti Chart جلوگیری کنید.

نکته دیگری که در رابطه با Line Chart مهم است، این است که نیازی نیست محور Y در این نمودار حتما از صفر شروع شود. گاهی نمایش آن از جایی بالاتر از صفر (زوم کردن روی نمودار)، الگوی تغییرات را بسیار بهتر نشان میدهد.

برای کسب اطلاعات بیشتر در رابطه با Line Chart اینجا کلیک کنید.
برای آشنایی با روشِ رسمِ Line Chart در زبان برنامهنویسی Python اینجا کلیک کنید.
۱۲. نمودار Area Chart
گاهی با رنگ زدنِ فضای زیرِ منحنیِ Line Chart و بررسیِ حجمِ رنگآمیزی شده در طول زمان، نوسانات و الگوی تکاملیِ متغیر، واضح تر میشود. معمولا از همان رنگِ استفاده شده برای منحنی با کمی Transparency برای رنگ زدن زیر منحنی استفاده میشود.

برای بررسی نوسانات چند متغیر به طور همزمان در یک Area Chart، مانند Line Chart عمل نمیکنیم. بلکه از نمودار های دیگر مثل Stacked Area Plot استفاده میشود.
برای کسب اطلاعات بیشتر در رابطه با Area Chart اینجا کلیک کنید.
برای آشنایی با روشِ رسمِ Area Chart در زبان برنامهنویسی Python اینجا کلیک کنید.
۱۳. نمودار Stacked Area Plot
برای نمایشِ روندِ تکاملِ چند متغیرِ عددی و یا نمایشِ روندِ تکاملِ یک متغیرِ عددی برای چندین گروه مختلف و مقایسه اهمیتِ نسبیِ آنها در یک نمودار، از Stacked Area Plot استفاده میشود. در این نمودار مقدار هر متغیر (یا گروه) در هر زمان، بر بالای منحنیِ مربوط به متغیرِ (گروه) قبلی، به صورت تجمعی رسم میشود. بنابراین بالاترین منحنی، معادلِ نمودار Area Plot برای مجموع همه متغیر ها (گروه ها) است.

برای کسب اطلاعات بیشتر در رابطه با Stacked Area Plot اینجا کلیک کنید.
برای آشنایی با روشِ رسمِ Stacked Area Plot در زبان برنامهنویسی Python اینجا کلیک کنید.
۱۴. نمودار Stream Graph
گاهی تنها چیزی که از یک Stacked Area Plot میخواهیم، نمایشِ نسبیِ سهمِ هر گروه (هر متغیر) از کل گروه ها طی یک بازه زمانی است. در چنین شرایطی میتوان از یک نوع خاص از Stacked Area Plot به نام Stream Graph استفاده کرد. در Stream Graph تیزی لبه ها گرفته شده و منحنی ها حول یک محور افقی رسم میشوند.
واضح است که چنین نموداری فقط منتقل کننده ی نسبتِ سهمِ هر گروه از کل است و برای بررسی الگوی تکاملی یک گروه خاص مناسب نیست.

برای کسب اطلاعات بیشتر در رابطه با Stream Graph اینجا کلیک کنید.
برای آشنایی با روشِ رسمِ Stream Graph در زبان برنامهنویسی Python اینجا کلیک کنید.
۱۵. نمودار Barplot
این نمودار برای نمایش رابطه ی بین یک متغیر دسته ای (Categorical) و یک متغیر عددی (Numerical) بکار میرود. طول Bar ها نشان دهنده اندازه متغیر عددی به ازای هر متغیر دسته ای است. توجه کنید که این نمودار را با Histogram اشتباه نگیرید. در Histogram همیشه یک متغیر عددی داریم که میخواهیم توزیع آماری آن را نمایش دهیم اما در Barplot یک متغیر دسته ای و یک متغیر عددی داریم و میخواهیم رابطه بین آنها را به تصویر بکشیم. اگر ترتیب مقادیر متغیر دسته ای اهمیتی ندارد، بهتر است آنها را به ترتیب مقدار عددی مرتب کنید تا نمودار خواناتری داشته باشید. زیرا در این صورت نمودار Barplot نه تنها نمایشگر مقدار عددی هر دسته است، بلکه ترتیب و رتبه ی هر دسته را نیز نشان میدهد.

اگر دو متغیر دسته ای موجود باشند میتوان از انواع زیر استفاده کرد:
- نمودار Grouped Barplot: مقادیر مربوط به متغیر دسته ای دوم کنار هم قرار میگیرند.
- نمودار Stacked Barplot: مقادیر مربوط به متغیر دسته ای دوم به صورت تجمعی روی هم قرار میگیرند.
- نمودار Percent-stacked Barplot: مقادیر مربوط به متغیر دسته ای دوم به صورت نسبی (درصدی) روی هم قرار میگیرند. به این معنی که مجموع آنها باید ۱۰۰ شود.

برای کسب اطلاعات بیشتر در رابطه با Barplot اینجا کلیک کنید.
برای آشنایی با روشِ رسمِ Barplot در زبان برنامهنویسی Python اینجا کلیک کنید.
۱۶. نمودار Lollipop Plot
همانطور که در شکل زیر مشخص است، زمانی که طول تعدادی از Bar های کنار هم در Barplot هم اندازه است، شکل ناهنجاری شبیه به کرکره ایجاد میشود. در این حالت، برای زیبایی بیشتر میتوان از Lollipop Plot استفاده کرد.

برای کسب اطلاعات بیشتر در رابطه با Lollipop Plot اینجا کلیک کنید.
برای آشنایی با روشِ رسمِ Lollipop Plot در زبان برنامهنویسی Python اینجا کلیک کنید.
۱۷. نمودار Pie Plot
برای نمایش دادنِ سهم مقادیر یک متغیر دسته ای از کل مقادیر، میتوان از Pie Plot استفاده کرد. در این نمودار به ازای هر متغیر دسته ای، یک برش از دایره در نظر گرفته میشود که زاویه ی آن بر اساس درصد سهم آن گروه از کل گروه ها تعیین میشود.

از آنجا که ذهن انسان در تشخیص و مقایسه سریع مفهوم زاویه خیلی خوب عمل نمیکند، بیشتر وقت ها، استفاده از این نمودار بدترین انتخاب ممکن است و بهتر است به جای آن از Barplot استفاده شود. برای نمونه سعی کنید در Pie Plot های زیر، برش ها را از کوچکترین به بزرگترین پیدا و مرتب کنید.

حال نتیجه را با تصویر زیر مقایسه کنید!

برای کسب اطلاعات بیشتر در رابطه با Pie Plot اینجا کلیک کنید.
برای آشنایی با روشِ رسمِ Pie Plot در زبان برنامهنویسی Python اینجا کلیک کنید.
۱۸. نمودار Radar Chart
زمانی که تعدادی متغیر کمّی وجود دارد و میخواهیم تعداد اندکی از مشاهدات مربوط به این متغیر ها را نشان دهیم، میتوانیم از Radar Chart (نامهای دیگر: Spider Chart و Web Chart) استفاده کنیم. در این نمودار، هر مشاهده شکل ظاهری مختص به خود را دارد.

برای کسب اطلاعات بیشتر در رابطه با Radar Chart اینجا کلیک کنید.
برای آشنایی با روشِ رسمِ Radar Chart در زبان برنامهنویسی Python اینجا کلیک کنید.
۱۹. نمودار Parallel Plot
زمانی که تعدادی متغیر کمّی وجود دارد و میخواهیم تعداد زیادی از مشاهدات مربوط به این متغیر ها را در یک شکل، نشان دهیم، میتوانیم از Parallel Plot (نام کاملتر: Parallel Coordinates Plot) استفاده کنیم. در این نمودار، هر محورِ عمودی، معرف یک Feature (متغیر) است که میتواند واحد خود را داشته باشد و مشاهدات توسط خطوطی که نقاطِ روی محور های عمودی را قطع میکنند نشان داده میشوند. همانطور که در شکل دیده میشود، میتوان از خطوط رنگی برای دسته بندی مشاهدات استفاده کرد.

برای کسب اطلاعات بیشتر در رابطه با Parallel Plot اینجا کلیک کنید.
برای آشنایی با روشِ رسمِ Parallel Plot در زبان برنامهنویسی Python اینجا کلیک کنید.
۲۰. سایر نمودار ها
تا اینجا با ۱۹ عدد از پرکاربردترین نمودار ها در Data Visualization آشنا شدید، اما همانطور که قبلا هم اشاره شد، اینها فقط تعدادی از نمودار های آماری موجود برای به تصویر کشیدن داده ها اند و میتوانید با مراجعه به سایت data-to-viz.com با سایر نمودار ها نیز آشنا شوید.

حال که با مهمترین نمودار های آماریِ مورد استفاده در Data Visualization و کاربردهای آنها آشنا شدید، اکیداً توصیه میکنیم برای جمعبندی مطالب، لینک های زیر را به ترتیب مطالعه کنید. در این لینک ها، Dataset هایی (به ترتیب از موارد ساده تر تا پیچیده تر) معرفی شده و با استفاده از نمودار های معرفی شده در این پست مورد مطالعه و تحلیل قرار گرفته اند.
https://www.data-to-viz.com/story/OneNum.htm
https://www.data-to-viz.com/story/TwoNum.html
https://www.data-to-viz.com/story/TwoNumOrdered.html
https://www.data-to-viz.com/story/ThreeNum.html
https://www.data-to-viz.com/story/OneCatSevOrderedNum.html
https://www.data-to-viz.com/story/SeveralNum.html
https://www.data-to-viz.com/story/SevCatOneNumNestedOneObsPerGroup.html
https://www.data-to-viz.com/story/OneNumOneCat.html
https://www.data-to-viz.com/story/OneNumOneCatSeveralObs.html
همینطور برای آشنایی با روش پیادهسازی و رسم نمودار های بالا با استفاده از کتابخانه Matplotlib در زبان برنامهنویسی Python پیشنهاد میشود ویدیوی آموزش Matplotlib در مکتبخونه را تماشا کنید.
منبع: https://vrgl.ir/iqWnF